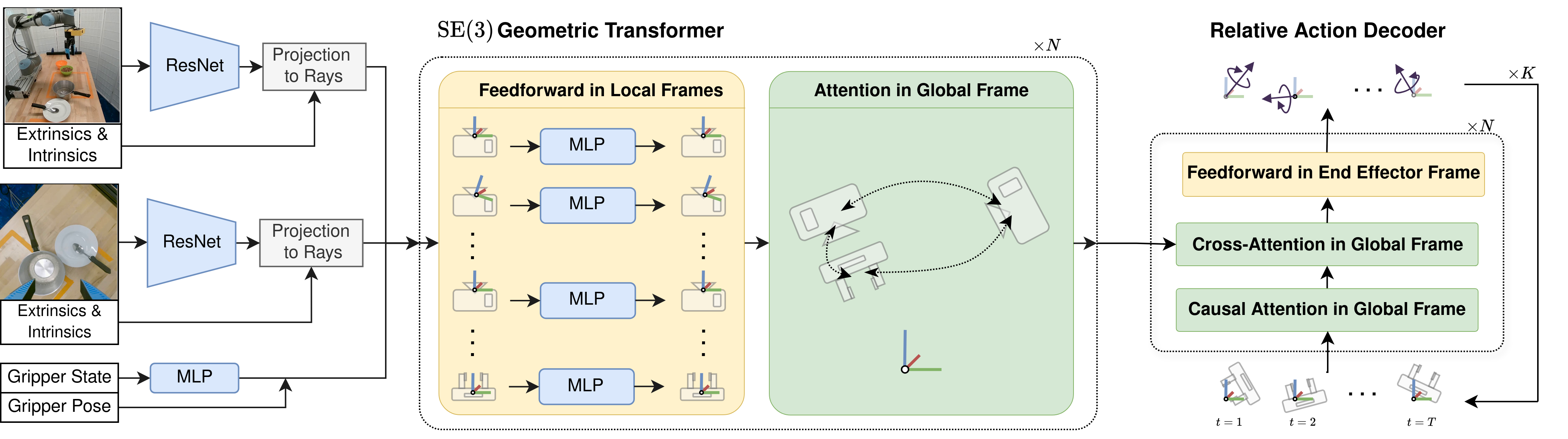
Idea
Goal. Bring the benefits of equivariance to image-based robot learning.
Key idea. Associate image features with SE(3) geometric representations and use geometric transform attention to process observations from multiple, stationary or moving cameras.
Takeaway. Our method achieves SE(3) equivariance to global transformations without imposing constraints on layout or number of cameras.
RAVEN Architecture